Claude Opus 4.5: The New AI Benchmark Leader
Okay, let's talk about something that's been making waves in the AI world. Anthropic just dropped Claude Opus 4.5, and honestly? It's pretty impressive.
I've been testing it for the past few days, and I wanted to share what I've found - no hype, just real observations from someone who uses these tools daily.
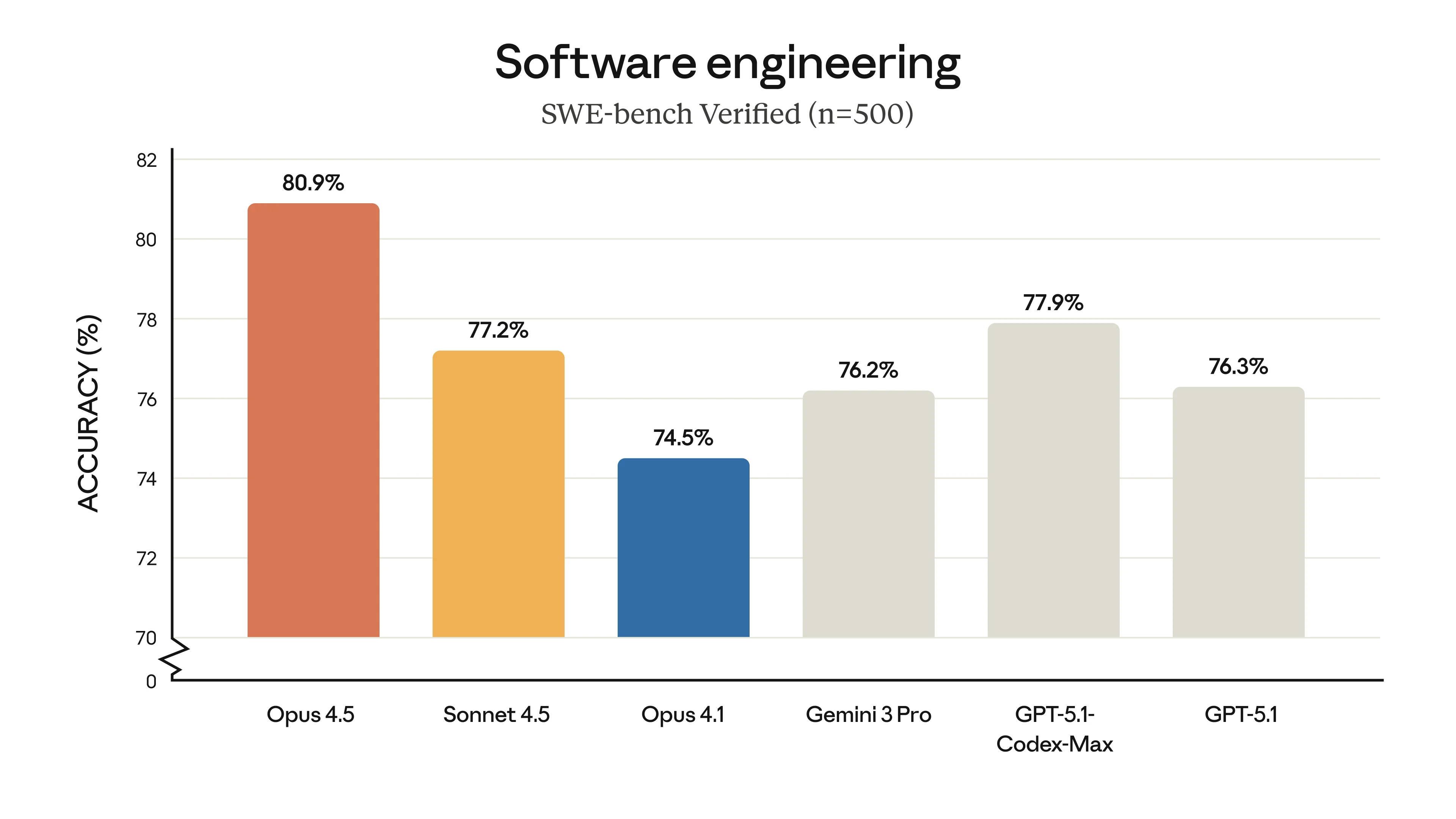
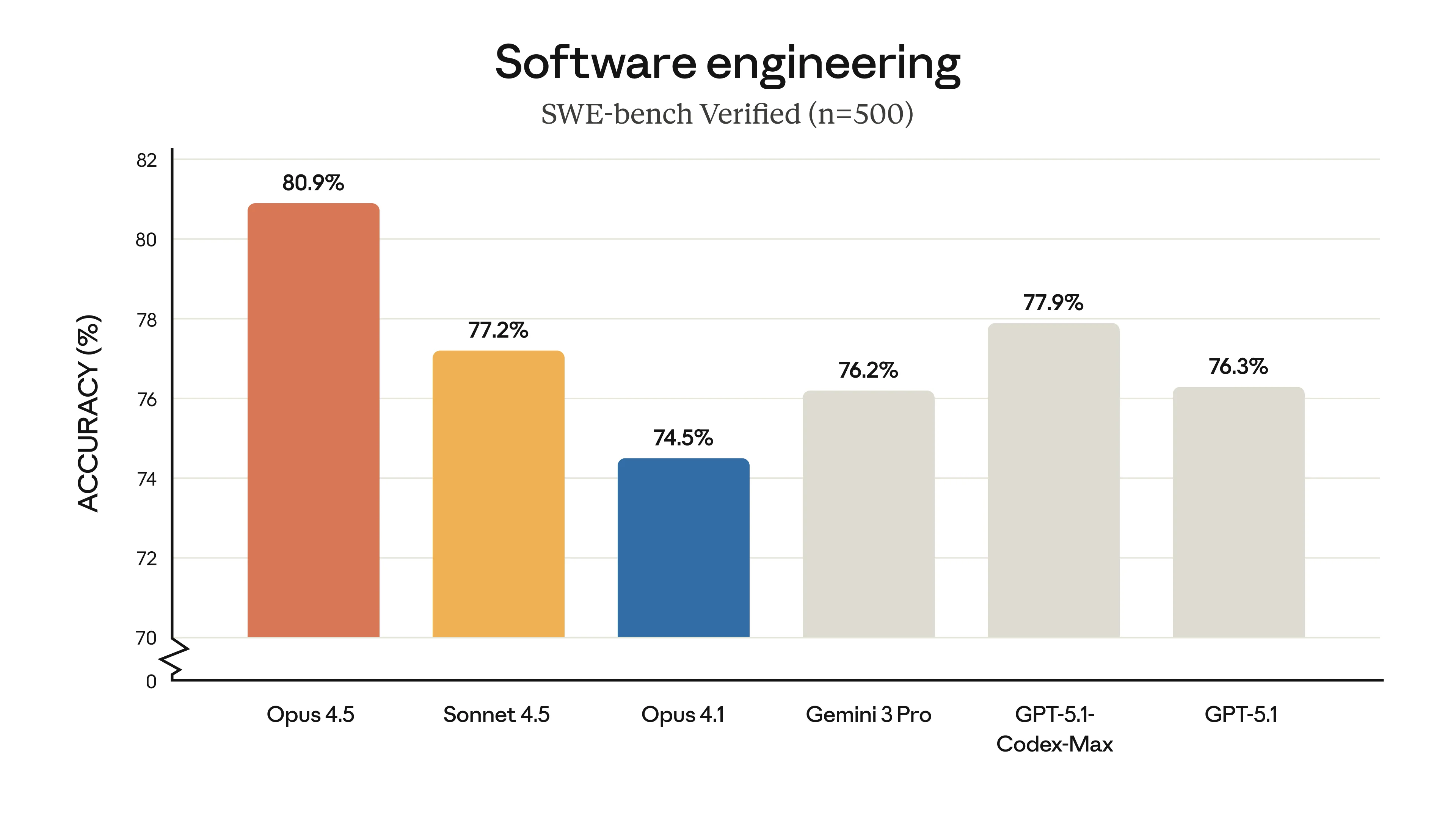 Claude Opus 4.5 SWE-bench Results
SWE-bench Verified results showing Claude Opus 4.5 leading the pack. Image: Anthropic
Claude Opus 4.5 SWE-bench Results
SWE-bench Verified results showing Claude Opus 4.5 leading the pack. Image: Anthropic
Why Should You Care?
Here's the thing - we get new AI models every few weeks now. Most are incremental improvements. But Opus 4.5 actually delivers something different: it's genuinely better at complex tasks.
I ran it through some of my trickiest client projects - the kind where previous models would stumble or give me half-baked answers. The difference was noticeable. Not perfect, but noticeably better.
 Mind blown reaction
Mind blown reaction
The Benchmarks (Yes, They Matter)
I know, I know - benchmarks can be misleading. But these numbers tell a story worth hearing:
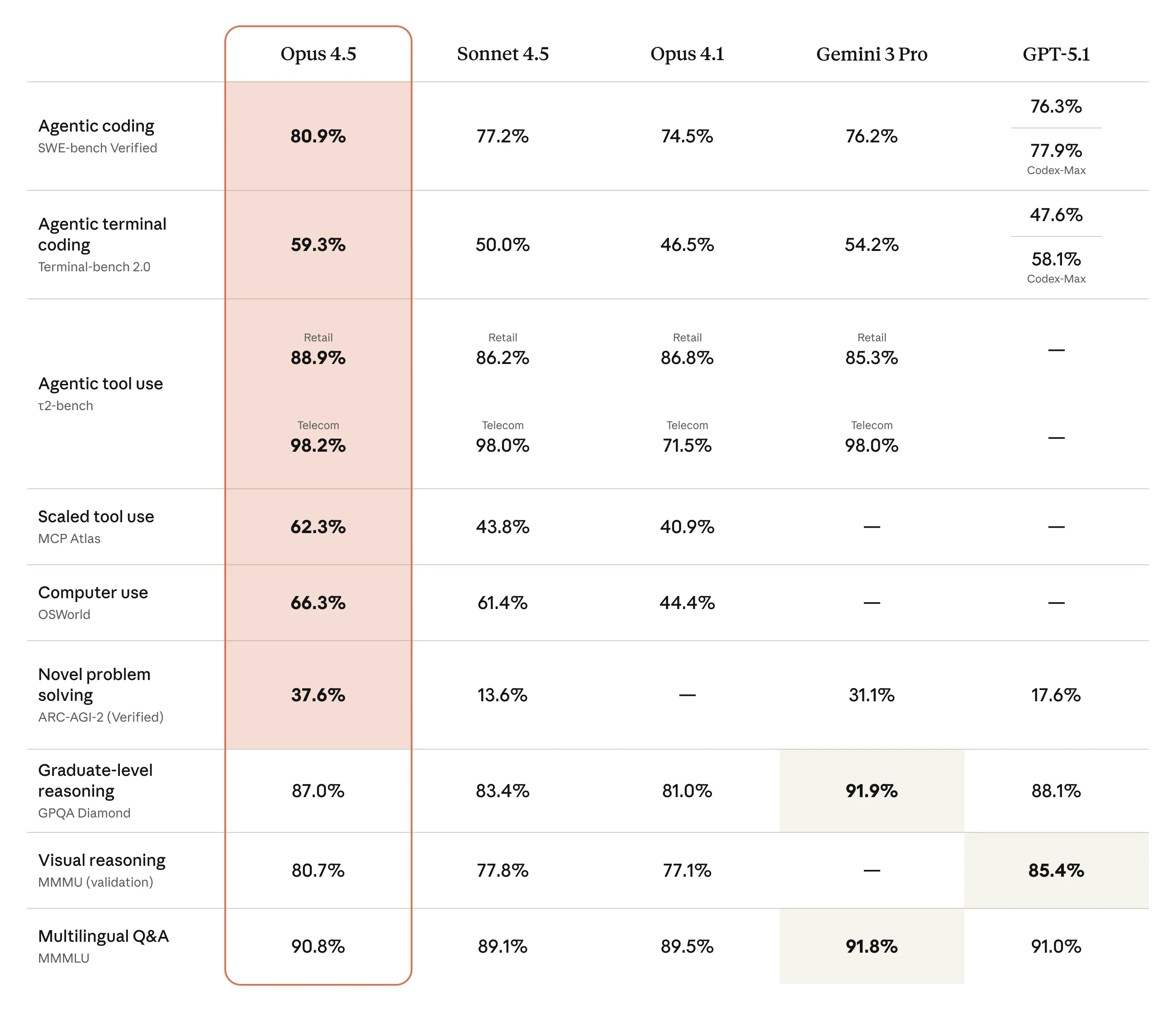 Claude Opus 4.5 Benchmark Comparison
Full benchmark comparison across frontier models. Image: Anthropic
Claude Opus 4.5 Benchmark Comparison
Full benchmark comparison across frontier models. Image: Anthropic
The Headline Numbers
| What It Does | Score | Why It Matters |
|---|---|---|
| SWE-bench Verified | 80.9% | Real GitHub issues, real solutions |
| OSWorld | 66.3% | Best at using computers autonomously |
| Terminal-Bench Hard | 44% | Complex command-line tasks |
That 80.9% on SWE-bench? That's not solving toy problems - it's fixing actual bugs in real codebases. The kind of stuff that takes developers hours to debug.
Real Talk: What's Actually Better?
Let me be specific about what I've noticed:
1. It Actually Finishes Complex Tasks
Previous models would often get 80% of the way through a complex task and then... trail off or make mistakes. Opus 4.5 has this ability to stay on track for much longer. I've had it work through 30+ minute coding sessions without losing the plot.
2. It Handles Ambiguity Better
You know how you sometimes have to write super detailed prompts to get good results? Opus 4.5 seems to "get it" faster. Less hand-holding required.
 Success celebration
Success celebration
3. Fewer Tokens, Same Quality
Here's something cool: at "medium effort" mode, it matches the previous Sonnet model's quality while using 76% fewer tokens. That's real cost savings.
How Does It Compare to GPT-5 and Gemini?
Alright, the question everyone's asking. Here's my honest take:
Claude Opus 4.5 wins at:
- Complex coding tasks (clear leader)
- Long, multi-step reasoning
- Staying "on brand" with your instructions
- Safety and resisting prompt injection
GPT-5.1 wins at:
- Visual understanding (still the best here)
- General flexibility
- Price ($1.25/$10 vs $5/$25 per million tokens)
Gemini 3 Pro wins at:
- Massive context windows (1M tokens!)
- Speed for simpler tasks
- Google ecosystem integration
The reality? I use all three depending on the task. But for serious coding work, Opus 4.5 has become my go-to.
The Safety Angle (It Actually Matters)
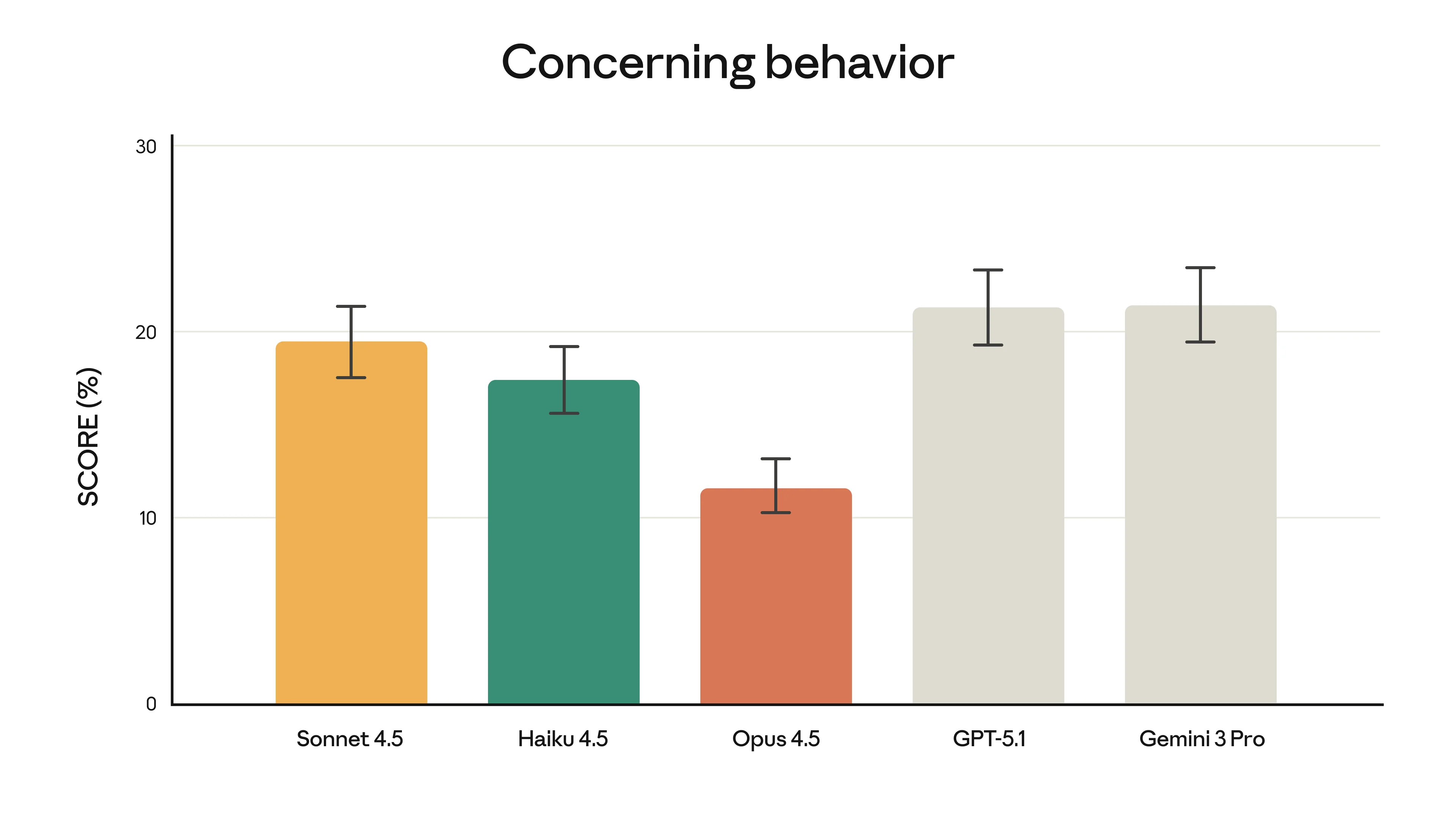 Claude Opus 4.5 Safety Metrics
Safety evaluation results showing improved robustness. Image: Anthropic
Claude Opus 4.5 Safety Metrics
Safety evaluation results showing improved robustness. Image: Anthropic
This might sound boring, but it's actually important: Anthropic claims Opus 4.5 is the hardest model to trick with prompt injection attacks.
Why does this matter? If you're building tools for clients or automating workflows with sensitive data, you need AI that doesn't get manipulated. This isn't about being overly cautious - it's about reliability.
Pricing: Let's Be Honest
Opus 4.5 isn't cheap:
- $5 per million input tokens
- $25 per million output tokens
That's more than GPT-5.1 ($1.25/$10) but way cheaper than the old Opus ($15/$75).
Here's my calculation: If it solves problems faster and with fewer retries, the premium pays for itself. For simple tasks? Use something cheaper. For complex work? The quality is worth it.
Money-saving tips:
- Use prompt caching (up to 90% savings)
- Batch processing (50% off)
- Use the "effort" parameter - dial it down for simpler tasks
My Recommendation
 Thinking about it
Thinking about it
Use Opus 4.5 when:
- You're doing complex coding or debugging
- You need reliable, long-running autonomous tasks
- Accuracy matters more than speed
- You're building AI-powered tools for clients
Use something else when:
- Simple queries or quick lookups
- You need massive context windows
- Budget is the primary concern
- Visual analysis is the main task
Getting Started
Want to try it? Here's how:
- Claude.ai - Available for Pro subscribers
- API - Model ID:
claude-opus-4-5-20251101 - Cloud - Available on AWS Bedrock, Google Vertex AI, Azure
Start with a specific problem you've struggled with before. See if it handles it better. That's the real test.
Bottom Line
Claude Opus 4.5 isn't perfect, but it's a genuine step forward for complex AI tasks. The benchmarks are impressive, but more importantly, it feels more capable when you use it.
Is it worth switching to? For serious coding and reasoning work, yes. For casual use, probably not worth the premium.
The AI landscape keeps evolving. What matters is finding the right tool for each job - and for complex work, Opus 4.5 just became a strong contender.
Questions about which AI tools are right for your business? Let's chat - I help companies figure this stuff out every day.
Image Credits: All benchmark images and data from Anthropic's official announcement. GIFs via Giphy.
Sources:


