Claude Opus 4.5: Der neue KI-Benchmark-Leader
Okay, reden wir mal über etwas, das gerade die KI-Welt aufmischt. Anthropic hat Claude Opus 4.5 veröffentlicht, und ehrlich gesagt? Es ist ziemlich beeindruckend.
Ich teste es jetzt seit ein paar Tagen und wollte meine Eindrücke teilen - kein Hype, nur echte Beobachtungen von jemandem, der diese Tools täglich nutzt.
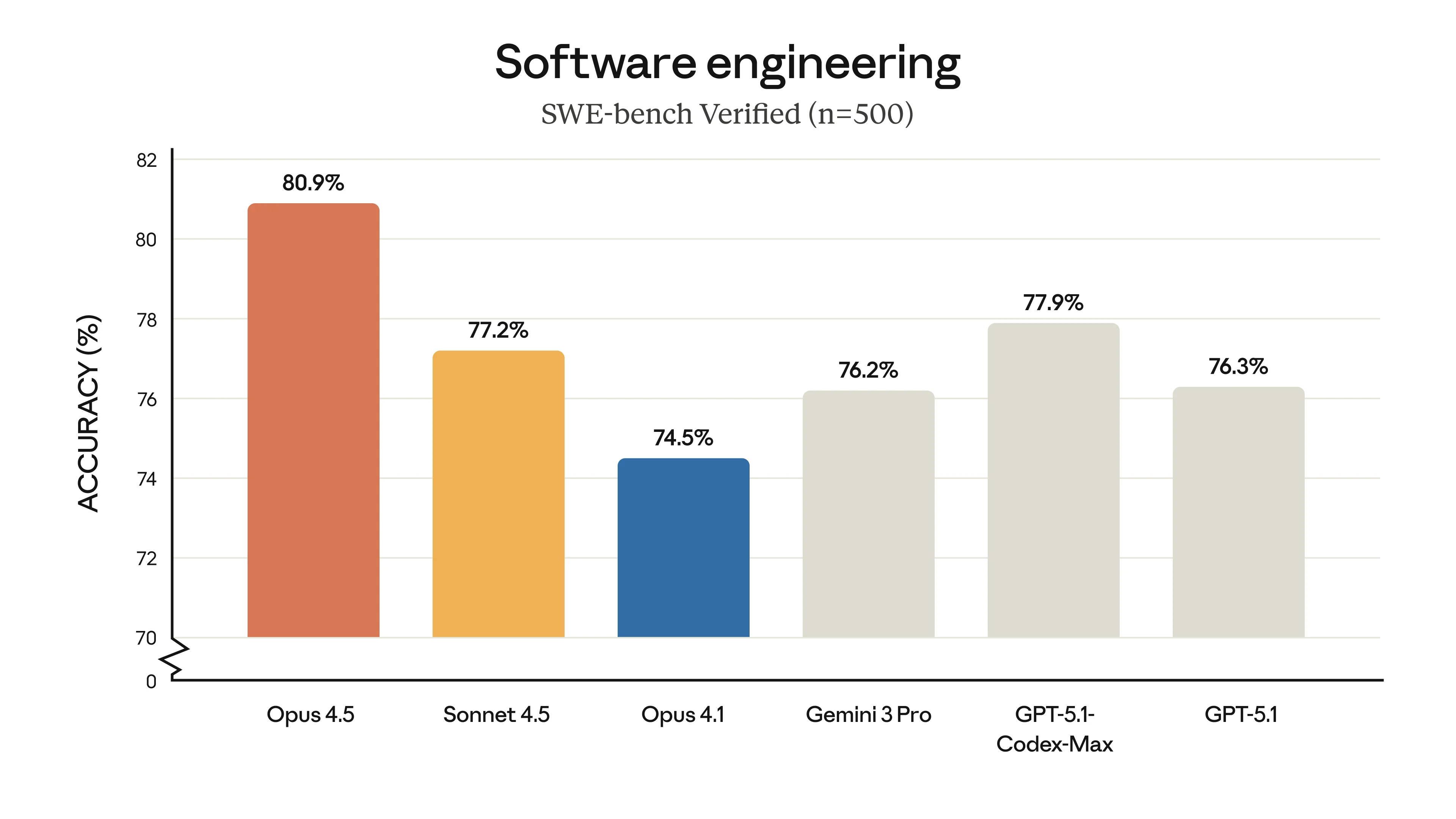
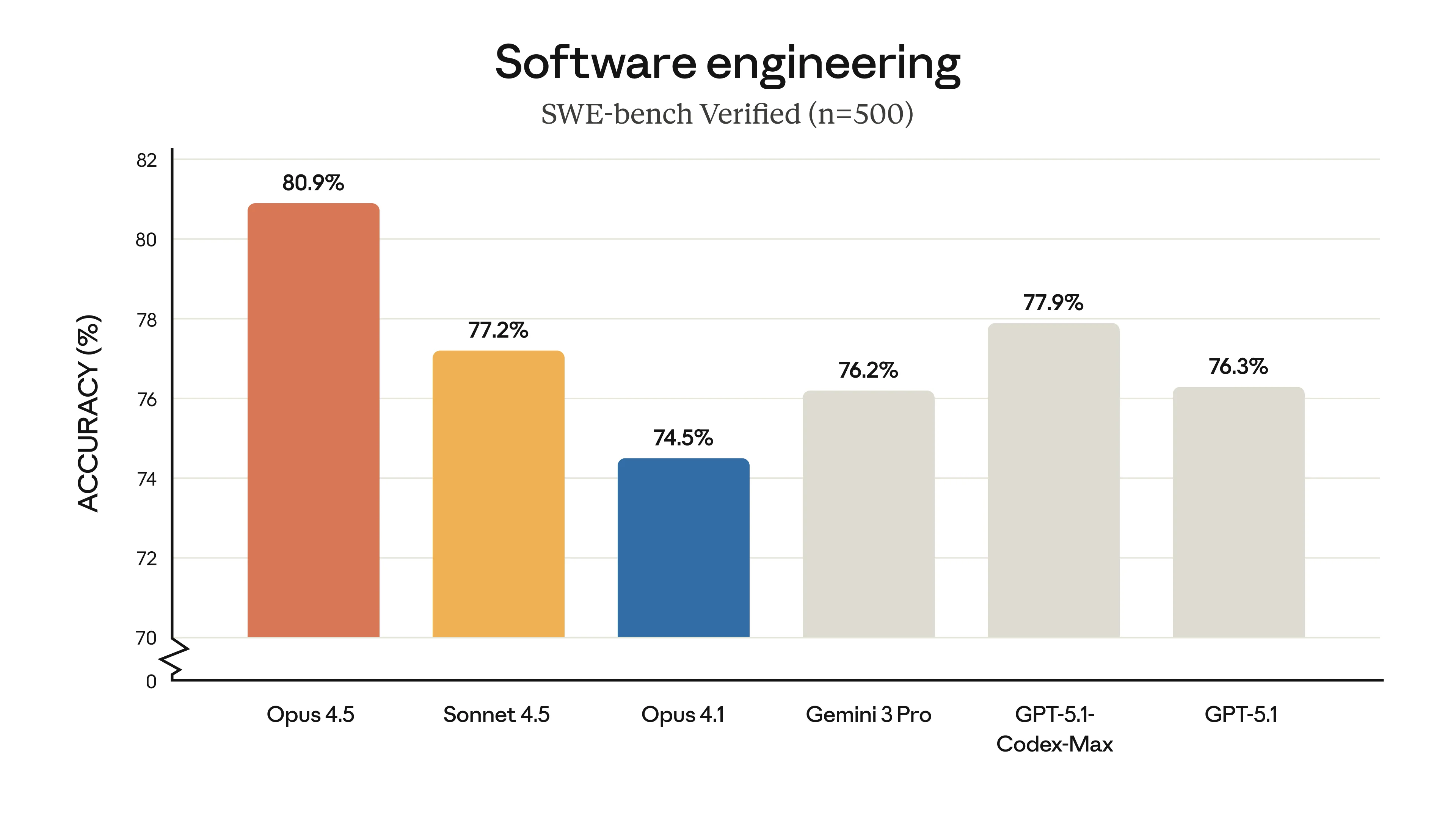 Claude Opus 4.5 SWE-bench Ergebnisse
SWE-bench Verified Ergebnisse zeigen Claude Opus 4.5 an der Spitze. Bild: Anthropic
Claude Opus 4.5 SWE-bench Ergebnisse
SWE-bench Verified Ergebnisse zeigen Claude Opus 4.5 an der Spitze. Bild: Anthropic
Warum sollte dich das interessieren?
Hier ist die Sache - wir bekommen jetzt alle paar Wochen neue KI-Modelle. Die meisten sind inkrementelle Verbesserungen. Aber Opus 4.5 liefert tatsächlich etwas anderes: Es ist wirklich besser bei komplexen Aufgaben.
Ich habe es mit einigen meiner kniffligsten Kundenprojekte getestet - die Art, bei der vorherige Modelle ins Stolpern kamen oder mir halbgare Antworten gaben. Der Unterschied war spürbar. Nicht perfekt, aber merklich besser.
 Mind blown Reaktion
Mind blown Reaktion
Die Benchmarks (ja, sie sind wichtig)
Ich weiß, ich weiß - Benchmarks können irreführend sein. Aber diese Zahlen erzählen eine Geschichte, die es wert ist, gehört zu werden:
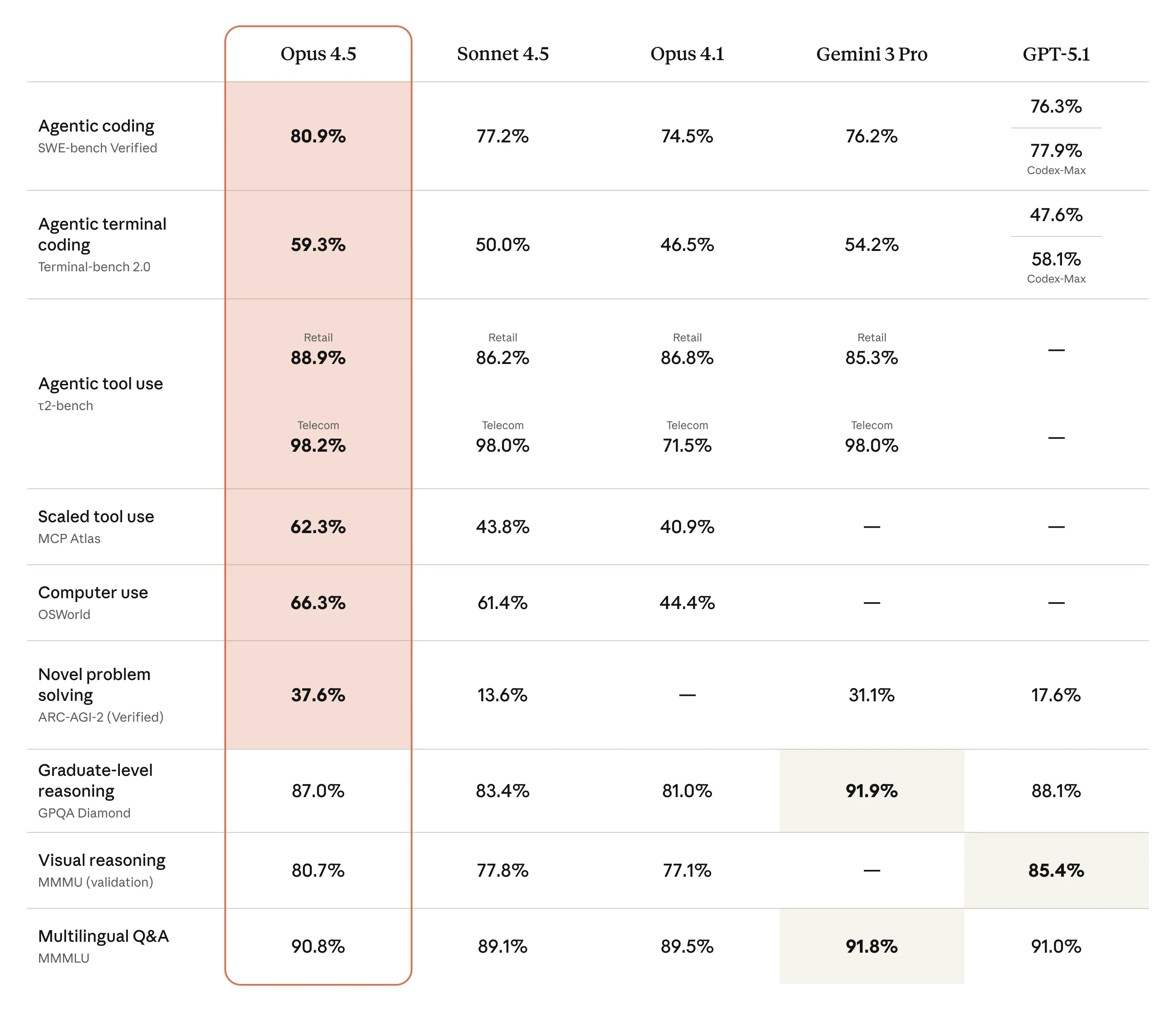 Claude Opus 4.5 Benchmark Vergleich
Vollständiger Benchmark-Vergleich der führenden Modelle. Bild: Anthropic
Claude Opus 4.5 Benchmark Vergleich
Vollständiger Benchmark-Vergleich der führenden Modelle. Bild: Anthropic
Die Schlagzeilen-Zahlen
| Was es kann | Punktzahl | Warum es wichtig ist |
|---|---|---|
| SWE-bench Verified | 80,9% | Echte GitHub-Issues, echte Lösungen |
| OSWorld | 66,3% | Das Beste bei autonomer Computernutzung |
| Terminal-Bench Hard | 44% | Komplexe Kommandozeilen-Aufgaben |
Diese 80,9% auf SWE-bench? Das sind keine Spielzeug-Probleme - das ist das Beheben echter Bugs in echten Codebasen. Die Art von Sachen, für die Entwickler Stunden zum Debuggen brauchen.
Klartext: Was ist wirklich besser?
Lass mich konkret werden, was mir aufgefallen ist:
1. Es schließt komplexe Aufgaben tatsächlich ab
Frühere Modelle kamen oft 80% des Weges durch eine komplexe Aufgabe und dann... verloren den Faden oder machten Fehler. Opus 4.5 hat diese Fähigkeit, viel länger auf Kurs zu bleiben. Ich hatte 30+ Minuten Coding-Sessions ohne dass es den Faden verlor.
2. Es geht besser mit Mehrdeutigkeit um
Du kennst das, wenn du manchmal super detaillierte Prompts schreiben musst, um gute Ergebnisse zu bekommen? Opus 4.5 scheint es schneller zu "kapieren". Weniger Händchenhalten nötig.
 Erfolgs-Feier
Erfolgs-Feier
3. Weniger Tokens, gleiche Qualität
Hier ist was Cooles: Im "medium effort" Modus erreicht es die Qualität des vorherigen Sonnet-Modells mit 76% weniger Tokens. Das sind echte Kosteneinsparungen.
Wie schneidet es gegen GPT-5 und Gemini ab?
Okay, die Frage, die alle stellen. Hier ist meine ehrliche Einschätzung:
Claude Opus 4.5 gewinnt bei:
- Komplexen Coding-Aufgaben (klarer Anführer)
- Langem, mehrstufigem Reasoning
- Konsistenz mit deinen Anweisungen
- Sicherheit und Resistenz gegen Prompt Injection
GPT-5.1 gewinnt bei:
- Visuellem Verständnis (immer noch das Beste hier)
- Allgemeiner Flexibilität
- Preis ($1,25/$10 vs $5/$25 pro Million Tokens)
Gemini 3 Pro gewinnt bei:
- Riesigen Kontextfenstern (1M Tokens!)
- Geschwindigkeit bei einfacheren Aufgaben
- Google-Ökosystem-Integration
Die Realität? Ich nutze alle drei je nach Aufgabe. Aber für ernsthafte Coding-Arbeit ist Opus 4.5 mein Favorit geworden.
Der Sicherheits-Aspekt (er ist tatsächlich wichtig)
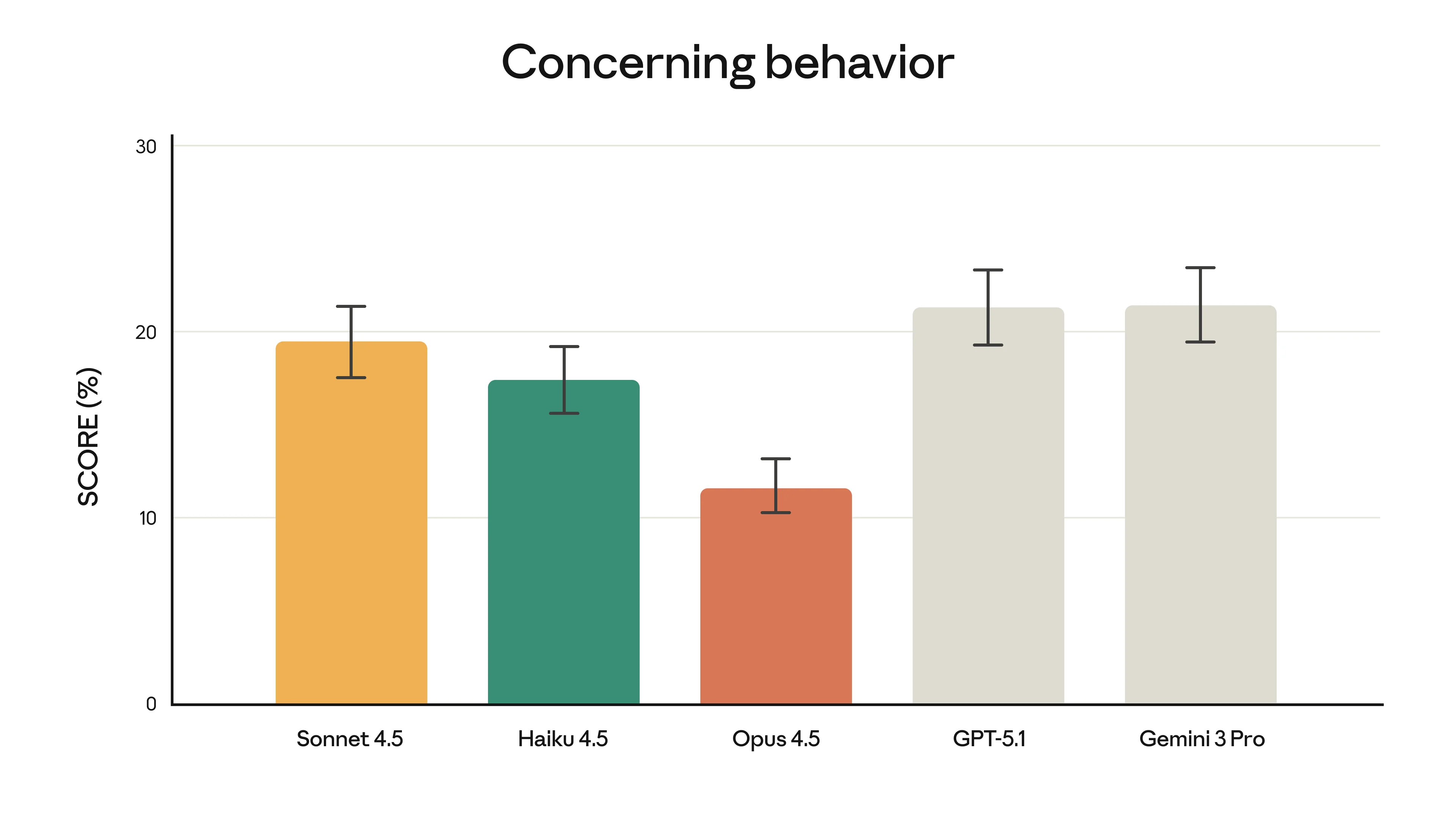 Claude Opus 4.5 Sicherheits-Metriken
Sicherheitsbewertung zeigt verbesserte Robustheit. Bild: Anthropic
Claude Opus 4.5 Sicherheits-Metriken
Sicherheitsbewertung zeigt verbesserte Robustheit. Bild: Anthropic
Das mag langweilig klingen, aber es ist wichtig: Anthropic behauptet, Opus 4.5 sei das am schwersten zu manipulierende Modell bei Prompt-Injection-Angriffen.
Warum ist das wichtig? Wenn du Tools für Kunden baust oder Workflows mit sensiblen Daten automatisierst, brauchst du KI, die sich nicht manipulieren lässt. Das ist keine übertriebene Vorsicht - das ist Zuverlässigkeit.
Gerade für Unternehmen im DACH-Raum, wo Datenschutz groß geschrieben wird, ist das besonders relevant.
Preise: Lass uns ehrlich sein
Opus 4.5 ist nicht billig:
- $5 pro Million Input-Tokens
- $25 pro Million Output-Tokens
Das ist mehr als GPT-5.1 ($1,25/$10), aber viel günstiger als das alte Opus ($15/$75).
Meine Rechnung: Wenn es Probleme schneller und mit weniger Anläufen löst, zahlt sich der Aufpreis selbst. Für einfache Aufgaben? Nimm was Günstigeres. Für komplexe Arbeit? Die Qualität ist es wert.
Spartipps:
- Prompt Caching nutzen (bis zu 90% Ersparnis)
- Batch-Verarbeitung (50% Rabatt)
- Den "effort"-Parameter nutzen - für einfachere Aufgaben runterdrehen
Meine Empfehlung
 Darüber nachdenken
Darüber nachdenken
Nutze Opus 4.5 wenn:
- Du komplexes Coding oder Debugging machst
- Du zuverlässige, lang laufende autonome Tasks brauchst
- Genauigkeit wichtiger als Geschwindigkeit ist
- Du KI-gestützte Tools für Kunden baust
Nimm was anderes wenn:
- Einfache Anfragen oder schnelle Lookups
- Du riesige Kontextfenster brauchst
- Budget die Hauptrolle spielt
- Visuelle Analyse die Hauptaufgabe ist
Erste Schritte
Willst du es ausprobieren? So geht's:
- Claude.ai - Verfügbar für Pro-Abonnenten
- API - Modell-ID:
claude-opus-4-5-20251101 - Cloud - Verfügbar auf AWS Bedrock, Google Vertex AI, Azure
Starte mit einem konkreten Problem, mit dem du vorher gekämpft hast. Schau, ob es das besser handhabt. Das ist der echte Test.
Fazit
Claude Opus 4.5 ist nicht perfekt, aber es ist ein echter Fortschritt für komplexe KI-Aufgaben. Die Benchmarks sind beeindruckend, aber wichtiger noch: Es fühlt sich fähiger an, wenn man es benutzt.
Lohnt sich der Wechsel? Für ernsthafte Coding- und Reasoning-Arbeit, ja. Für Casual-Nutzung wahrscheinlich nicht den Aufpreis wert.
Die KI-Landschaft entwickelt sich weiter. Was zählt, ist das richtige Tool für jeden Job zu finden - und für komplexe Arbeit ist Opus 4.5 gerade ein starker Kandidat geworden.
Fragen dazu, welche KI-Tools die richtigen für dein Unternehmen sind? Lass uns reden - ich helfe Unternehmen täglich bei genau solchen Entscheidungen.
Bildnachweis: Alle Benchmark-Bilder und Daten aus Anthropics offizieller Ankündigung. GIFs via Giphy.
Quellen: